Bayesian Regression in PYMC3 using MCMC & Variational Inference
Posted on Wed 07 November 2018 in data-science
![]()
Conducting a Bayesian data analysis - e.g. estimating a Bayesian linear regression model - will usually require some form of Probabilistic Programming Language (PPL), unless analytical approaches (e.g. based on conjugate prior models), are appropriate for the task at hand. More often than not, PPLs implement Markov Chain Monte Carlo (MCMC) algorithms that allow one to draw samples and make inferences from the posterior distribution implied by the choice of model - the likelihood and prior distributions for its parameters - conditional on the observed data.
MCMC algorithms are, generally speaking, computationally expensive and do not scale very easily. For example, it is not as easy to distribute the execution of these algorithms over a cluster of machines, when compared to the optimisation algorithms used for training deep neural networks (e.g. stochastic gradient descent).
Over the past few years, however, a new class of algorithms for inferring Bayesian models has been developed, that do not rely heavily on computationally expensive random sampling. These algorithms are referred to as Variational Inference (VI) algorithms and have been shown to be successful with the potential to scale to ‘large’ datasets.
My preferred PPL is PYMC3 and offers a choice of both MCMC and VI algorithms for inferring models in Bayesian data analysis. This blog post is based on a Jupyter notebook located in this GitHub repository, whose purpose is to demonstrate using PYMC3, how MCMC and VI can both be used to perform a simple linear regression, and to make a basic comparison of their results.
Table of Contents
- A (very) Quick Introduction to Bayesian Data Analysis
- Imports and Global Settings
- Create Synthetic Data
- Split Data into Training and Test Sets
- Define Bayesian Regression Model
- Model Inference Using MCMC (HMC)
- Model Inference using Variational Inference (mini-batch ADVI)
- Comparing Predictions
- Conclusions
A (very) Quick Introduction to Bayesian Data Analysis
Like statistical data analysis more broadly, the main aim of Bayesian Data Analysis (BDA) is to infer unknown parameters for models of observed data, in order to test hypotheses about the physical processes that lead to the observations. Bayesian data analysis deviates from traditional statistics - on a practical level - when it comes to the explicit assimilation of prior knowledge regarding the uncertainty of the model parameters, into the statistical inference process and overall analysis workflow. To this end, BDA focuses on the posterior distribution,
$$ p(\Theta | X) = \frac{p(X | \Theta) \cdot p(\Theta)}{p(X)} $$
Where,
- $\Theta$ is the vector of unknown model parameters, that we wish to estimate;
- $X$ is the vector of observed data;
- $p(X | \Theta)$ is the likelihood function that models the probability of observing the data for a fixed choice of parameters; and,
- $p(\Theta)$ is the prior distribution of the model parameters.
For an excellent (inspirational) introduction to practical BDA, take a look at Statistical Rethinking by Richard McElreath, or for a more theoretical treatment try Bayesian Data Analysis by Gelman & co..
This notebook is concerned with demonstrating and comparing two separate approaches for inferring the posterior distribution, $p(\Theta | X)$, for a linear regression model.
Imports and Global Settings
Before we get going in earnest, we follow the convention of declaring all imports at the top of the notebook.
import numpy as np
import pandas as pd
import pymc3 as pm
import seaborn as sns
import theano
import warnings
from numpy.random import binomial, randn, uniform
from sklearn.model_selection import train_test_split
And then notebook-wide (global) settings that enable in-line plotting, configure Seaborn for visualisation and to explicitly ignore warnings (e.g. NumPy deprecations).
%matplotlib inline
sns.set()
warnings.filterwarnings('ignore')
Create Synthetic Data
We will assume that there is a dependent variable (or labelled data) $\tilde{y}$, that is a linear function of independent variables (or feature data), $x$ and $c$. In this instance, $x$ is a positive real number and $c$ denotes membership to one of two categories that occur with equal likelihood. We express this model mathematically, as follows,
$$ \tilde{y} = \alpha_{c} + \beta_{c} \cdot x + \sigma \cdot \tilde{\epsilon} $$
where $\tilde{\epsilon} \sim N(0, 1)$, $\sigma$ is the standard deviation of the noise in the data and $c \in {0, 1}$ denotes the category. We start by defining our a priori choices for the model parameters.
alpha_0 = 1
alpha_1 = 1.25
beta_0 = 1
beta_1 = 1.25
sigma = 0.75
We then use these to generate some random samples that we store in a DataFrame and visualise using the Seaborn package.
n_samples = 1000
category = binomial(n=1, p=0.5, size=n_samples)
x = uniform(low=0, high=10, size=n_samples)
y = ((1 - category) * alpha_0 + category * alpha_1
+ ((1 - category) * beta_0 + category * beta_1) * x
+ sigma * randn(n_samples))
model_data = pd.DataFrame({'y': y, 'x': x, 'category': category})
display(model_data.head())
_ = sns.relplot(x='x', y='y', hue='category', data=model_data)
| y | x | category | |
|---|---|---|---|
| 0 | 3.429483 | 2.487456 | 1 |
| 1 | 6.987868 | 5.801619 | 0 |
| 2 | 3.340802 | 3.046879 | 0 |
| 3 | 8.826015 | 6.172437 | 1 |
| 4 | 10.659304 | 9.829751 | 0 |
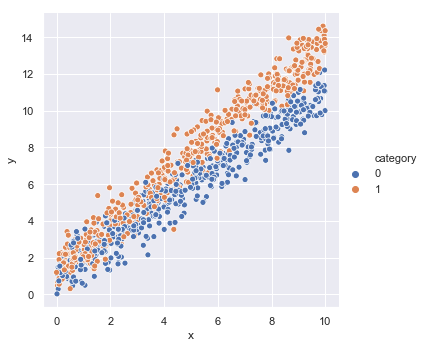
Split Data into Training and Test Sets
One of the advantages of generating synthetic data is that we can ensure we have enough data to be able to partition it into two sets - one for training models and one for testing models. We use a helper function from the Scikit-Learn package for this task and make use of stratified sampling to ensure that we have a balanced representation of each category in both training and test datasets.
train, test = train_test_split(
model_data, test_size=0.2, stratify=model_data.category)
We will be using the PYMC3 package for building and estimating our Bayesian regression models, which in-turn uses the Theano package as a computational ‘back-end’ (in much the same way that the Keras package for deep learning uses TensorFlow as back-end). Consequently, we will have to interact with Theano if we want to have the ability to swap between training and test data (which we do). As such, we will explicitly define ‘shared’ tensors for all of our model variables.
y_tensor = theano.shared(train.y.values.astype('float64'))
x_tensor = theano.shared(train.x.values.astype('float64'))
cat_tensor = theano.shared(train.category.values.astype('int64'))
Define Bayesian Regression Model
Now we move on to define the model that we want to estimate (i.e. our hypothesis regarding the data), irrespective of how we will perform the inference. We will assume full knowledge of the data-generating model we defined above and define conservative regularising priors for each of the model parameters.
with pm.Model() as model:
alpha_prior = pm.HalfNormal('alpha', sd=2, shape=2)
beta_prior = pm.Normal('beta', mu=0, sd=2, shape=2)
sigma_prior = pm.HalfNormal('sigma', sd=2, shape=1)
mu_likelihood = alpha_prior[cat_tensor] + beta_prior[cat_tensor] * x_tensor
y_likelihood = pm.Normal('y', mu=mu_likelihood, sd=sigma_prior, observed=y_tensor)
Model Inference Using MCMC (HMC)
We will make use of the default MCMC method in PYMC3’s sample function, which is Hamiltonian Monte Carlo (HMC). Those interested in the precise details of the HMC algorithm are directed to the excellent paper Michael Betancourt. Briefly, MCMC algorithms work by defining multi-dimensional Markovian stochastic processes, that when simulated (using Monte Carlo methods), will eventually converge to a state where successive simulations will be equivalent to drawing random samples from the posterior distribution of the model we wish to estimate.
The posterior distribution has one dimension for each model parameter, so we can then use the distribution of samples for each parameter to infer the range of possible values and/or compute point estimates (e.g. by taking the mean of all samples).
For the purposes of this demonstration, we sample two chains in parallel (as we have two CPU cores available for doing so and this effectively doubles the number of samples), allow 1,000 steps for each chain to converge to its steady-state and then sample for a further 5,000 steps - i.e. generate 5,000 samples from the posterior distribution, assuming that the chain has converged after 1,000 samples.
with model:
hmc_trace = pm.sample(draws=5000, tune=1000, cores=2)
Now let’s take a look at what we can infer from the HMC samples of the posterior distribution.
pm.traceplot(hmc_trace)
pm.summary(hmc_trace)
| mean | sd | mc_error | hpd_2.5 | hpd_97.5 | n_eff | Rhat | |
|---|---|---|---|---|---|---|---|
| beta__0 | 1.002347 | 0.013061 | 0.000159 | 0.977161 | 1.028955 | 5741.410305 | 0.999903 |
| beta__1 | 1.250504 | 0.012084 | 0.000172 | 1.226709 | 1.273830 | 5293.506143 | 1.000090 |
| alpha__0 | 0.989984 | 0.073328 | 0.000902 | 0.850417 | 1.141318 | 5661.466167 | 0.999900 |
| alpha__1 | 1.204203 | 0.069373 | 0.000900 | 1.069428 | 1.339139 | 5514.158012 | 1.000004 |
| sigma__0 | 0.734316 | 0.017956 | 0.000168 | 0.698726 | 0.768540 | 8925.864908 | 1.000337 |
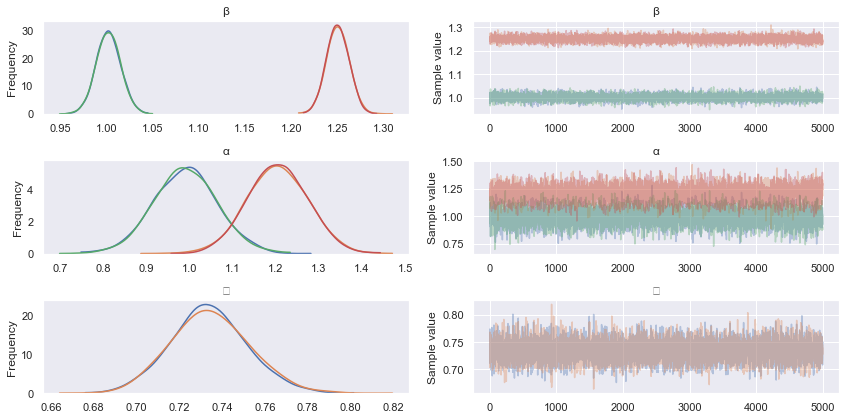
Firstly, note that Rhat values (the Gelman Rubin statistic) converging to 1 implies chain convergence for the marginal parameter distributions, while n_eff describes the effective number of samples after autocorrelations in the chains have been accounted for. We can see from the mean (point) estimate of each parameter that HMC has done a reasonable job of estimating our original parameters.
Model Inference using Variational Inference (mini-batch ADVI)
Variational Inference (VI) takes a completely different approach to inference. Briefly, VI is a name for a class of algorithms that seek to fit a chosen class of functions to approximate the posterior distribution, effectively turning inference into an optimisation problem. In this instance VI minimises the Kullback–Leibler (KL) divergence (a measure of the ‘similarity’ between two densities), between the approximated posterior density and the actual posterior density. An excellent review of VI can be found in the paper by Blei & co..
Just to make things more complicated (and for this description to be complete), the KL divergence is actually minimised, by maximising the Evidence Lower BOund (ELBO), which is equal to the negative of the KL divergence up to a constant term - a constant that is computationally infeasible to compute, which is why, technically, we are optimising ELBO and not the KL divergence, albeit to achieve the same end-goal.
We are going to make use of PYMC3’s Auto-Differentiation Variational Inference (ADVI) algorithm (full details in the paper by Kucukelbir & co.), which is capable of computing a VI for any differentiable posterior distribution (i.e. any model with continuous prior distributions). In order to achieve this very clever feat (the paper is well-worth a read), the algorithm first maps the posterior into a space where all prior distributions have the same support, such that they can be well approximated by fitting a spherical n-dimensional Gaussian distribution within this space - this is referred to as the ‘Gaussian mean-field approximation’. Note, that due to the initial transformation, this is not the same as approximating the posterior distribution using an n-dimensional Normal distribution. The parameters of these Gaussian parameters are then chosen to maximise the ELBO using gradient ascent - i.e. using high-performance auto-differentiation techniques in numerical computing back-ends such as Theano, TensorFlow, etc..
The assumption of a spherical Gaussian distribution does, however, imply no dependency (i.e. zero correlations) between parameter distributions. One of the advantages of HMC over ADVI, is that these correlations, which can lead to under-estimated variances in the parameter distributions, are included. ADVI gives these up in the name of computational efficiency (i.e. speed and scale of data). This simplifying assumption can be dropped, however, and PYMC3 does offer the option to use ‘full-rank’ Gaussians, but I have not used this in anger (yet).
We also take the opportunity to make use of PYMC3’s ability to compute ADVI using ‘batched’ data, analogous to how Stochastic Gradient Descent (SGD) is used to optimise loss functions in deep-neural networks, which further facilitates model training at scale thanks to the reliance on auto-differentiation and batched data, which can also be distributed across CPU (or GPUs).
In order to enable mini-batch ADVI, we first have to setup the mini-batches (we use batches of 100 samples).
map_tensor_batch = {y_tensor: pm.Minibatch(train.y.values, 100),
x_tensor: pm.Minibatch(train.x.values, 100),
cat_tensor: pm.Minibatch(train.category.values, 100)}
We then compute the variational inference using 30,000 iterations (for the gradient ascent of the ELBO). We use the more_replacements key-word argument to swap-out the original Theano tensors with the batched versions defined above.
with model:
advi_fit = pm.fit(method=pm.ADVI(), n=30000,
more_replacements=map_tensor_batch)
Before we take a look at the parameters, let’s make sure the ADVI fit has converged by plotting ELBO as a function of the number of iterations.
advi_elbo = pd.DataFrame(
{'log-ELBO': -np.log(advi_fit.hist),
'n': np.arange(advi_fit.hist.shape[0])})
_ = sns.lineplot(y='log-ELBO', x='n', data=advi_elbo)
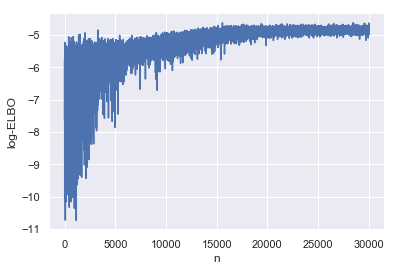
In order to be able to look at what we can infer from posterior distribution we have fit with ADVI, we first have to draw some samples from it, before summarising like we did with HMC inference.
advi_trace = advi_fit.sample(10000)
pm.traceplot(advi_trace)
pm.summary(advi_trace)
| mean | sd | mc_error | hpd_2.5 | hpd_97.5 | |
|---|---|---|---|---|---|
| beta__0 | 1.000717 | 0.022073 | 0.000220 | 0.957703 | 1.044096 |
| beta__1 | 1.250904 | 0.020917 | 0.000206 | 1.209715 | 1.292017 |
| alpha__0 | 0.984404 | 0.122010 | 0.001109 | 0.755816 | 1.230404 |
| alpha__1 | 1.192829 | 0.120833 | 0.001146 | 0.966362 | 1.433906 |
| sigma__0 | 0.760702 | 0.060009 | 0.000569 | 0.649582 | 0.883380 |
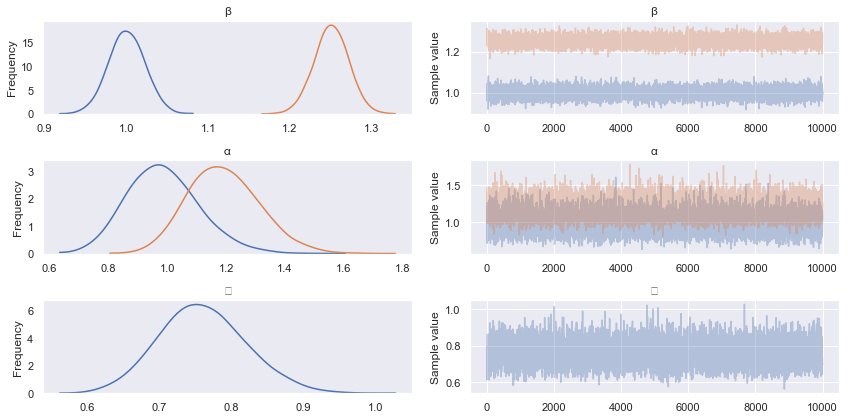
Not bad! The mean estimates are comparable, but we note that the standard deviations appear to be larger than those estimated with HMC.
Comparing Predictions
Let’s move on to comparing the inference algorithms on the practical task of making predictions on our test dataset. We start by swapping the test data into our Theano variables.
y_tensor.set_value(test.y.values)
x_tensor.set_value(test.x.values)
cat_tensor.set_value(test.category.values.astype('int64'))
And then drawing posterior-predictive samples for each new data-point, for which we use the mean as the point estimate to use for comparison.
hmc_posterior_pred = pm.sample_ppc(hmc_trace, 1000, model)
hmc_predictions = np.mean(hmc_posterior_pred['y'], axis=0)
advi_posterior_pred = pm.sample_ppc(advi_trace, 1000, model)
advi_predictions = np.mean(advi_posterior_pred['y'], axis=0)
prediction_data = pd.DataFrame(
{'HMC': hmc_predictions,
'ADVI': advi_predictions,
'actual': test.y,
'error_HMC': hmc_predictions - test.y,
'error_ADVI': advi_predictions - test.y})
_ = sns.lmplot(y='ADVI', x='HMC', data=prediction_data,
line_kws={'color': 'red', 'alpha': 0.5})
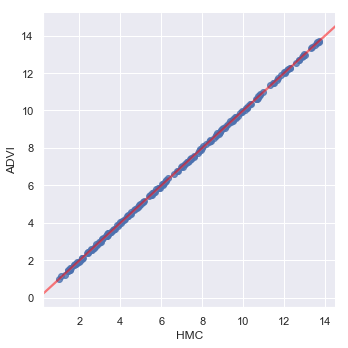
As we might expect, given the parameter estimates, the two models generate similar predictions.
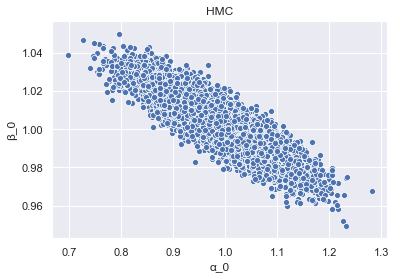
To begin to get an insight into the differences between HMC and ADVI, we look at the inferred dependency structure between the samples of alpha_0 and beta_0, for both HMC and VI, starting with HMC.
param_samples_HMC = pd.DataFrame(
{'alpha_0': hmc_trace.get_values('alpha')[:, 0],
'beta_0': hmc_trace.get_values('beta')[:, 0]})
_ = sns.scatterplot(x='alpha_0', y='beta_0', data=param_samples_HMC).set_title('HMC')
And again for ADVI.
param_samples_ADVI = pd.DataFrame(
{'alpha_0': advi_trace.get_values('alpha')[:, 0],
'beta_0': advi_trace.get_values('beta')[:, 0]})
_ = sns.scatterplot(x='alpha_0', y='beta_0', data=param_samples_ADVI).set_title('ADVI')
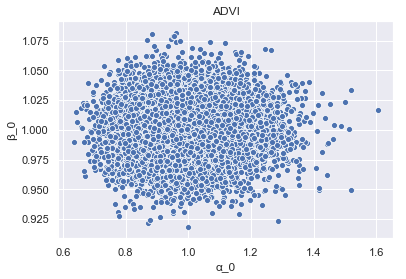
We can see clearly the impact of ADVI’s assumption of n-dimensional spherical Gaussians, manifest in the inference!
Finally, let’s compare predictions with the actual data.
RMSE = np.sqrt(np.mean(prediction_data.error_ADVI ** 2))
print(f'RMSE for ADVI predictions = {RMSE:.3f}')
_ = sns.lmplot(y='ADVI', x='actual', data=prediction_data,
line_kws={'color': 'red', 'alpha': 0.5})
RMSE for ADVI predictions = 0.746
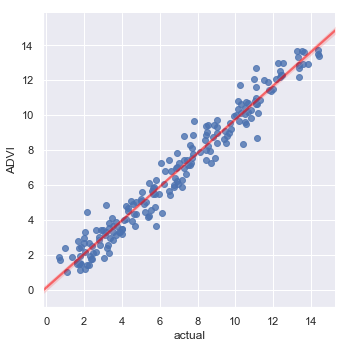
Which is what one might expect, given the data generating model.
Conclusions
MCMC and VI present two very different approaches for drawing inferences from Bayesian models. Despite these differences, their high-level output for a simplistic (but not entirely trivial) regression problem, based on synthetic data, is comparable regardless of the approximations used within ADVI. This is important to note, because general purpose VI algorithms such as ADVI have the potential to work at scale - on large volumes of data in a distributed computing environment (see the references embedded above, for case studies).